Topics:
1. Zoning
2. Host to Clariion Configurations
3. Host Connectivity Limitations
4. Storage Processor Ports WWNs
5. Caching
6. Cache Allocation
7. Cache Page Size
8. Enclosure Types
9. Cache WaterMarks
10. Verifying RAID Group Disk Order
11. LUN Layout
12. Calculating the Stripe Size of a LUN
13. Setting the Alignment Offset on ESX Server and a (Virtual) Windows Server
14. Setting Raid Group Command Parameters
15. Setting Cache Command Parameters
16. Setting the Alignment Offset for windows & Linux servers
17. Disk Alignment
18. LUN Migration
19. MetaLUNs
20. Access Logix
21. Clariion Disk Format
22. Disk Format
23. LUNs
24. Order of Disks in RAID Group for RAID 1_0
25. RAID GROUPS and RAID Types
26. Vault Drives
27. General Commands for Navisphere CLI
================================================================
Zoning

How a Host might be zoned through switches to a Clariion.
This host has two(2) Host Bus Adapters. From the previous page, we know that the host must have at least one connection to SP A and one connection to SP B. What we are illustrating here is from the “Host to Clariion Configuration” page, Configuration Three. We are also going to look at what is meant by “Single Inititiator Zoning”. Single Initiator Zoning means that you create a zone with one HBA entry. We don’t want to have a zone that would contain an HBAs from two(2) Hosts.
HBA1 is connected to Port 0 on the switch. SP A port 0 is connected to the same switch at Port 14. Based on the World Wide Names of HBA1 and SP A port 0, we can now create a zone through the switch software. The zone could look as follows:
Zone HBA1 to SP A port 0
10:00:00:00:07:36:55:86
50:06:01:60:10:60:08:74
We also want to connect HBA1 to SP B. We connect SP B port 0 to Port 15 on the same switch. That zone could look as follows:
Zone HBA1 to SP B port 0
10:00:00:00:07:36:55:86
50:06:01:68:10:60:08:74
HBA1 is now zoned and connected to both Storage Processors on the Clariion.
We would repeat the same steps for HBA2 and the switch that it is connected to. HBA2 is connected to Port 0 on the switch. SP A port 1 is connected to the same switch at Port 14. Based on the World Wide Names of HBA1 and SP A port 1, we can now create a zone through the switch software. The zone could look as follows:
Zone HBA2 to SP A port 1
10:00:00:00:66:87:35:20
50:06:01:61:10:60:08:74
We also want to connect HBA2 to SP B. We connect SP B port 1 to Port 15 on the same switch. That zone could look as follows:
Zone HBA2 to SP B port 1
10:00:00:00:66:87:35:20
50:06:01:69:10:60:08:74
Another way in which the zoning could have been done is:
Zone HBA1 to SP A port 0 and SP B port 0
10:00:00:00:07:36:55:86
50:06:01:60:10:60:08:74
50:06:01:68:10:60:08:74
Again, there is only one HBA in that zone. The preferred method is simply up to you and how you want to manage the switches. The advantage of doing it this way is that it cuts the number of zones on the switch in half, but could be a little confusing (which could be nice for job security).
Now, what do we do if there is an HBA failure? First of all, that never happens. (Kidding) This is where we go to the four(4) steps listed under HBA Failure. The three R’s and a D. Let’s say that HBA1 were do fail. The first thing we would do is to replace that failed HBA. Next, because we did our zoning on the switch based on the World Wide Names of the HBAs, we would have to rezone the switch for the new HBA because it would have a new World Wide Name. The third step is to go to Navisphere, and using Connectivity Status, Register the new HBA with the Clariion. And finally, the Clariion does not automatically clean itself up. You would have to again, in Connectivity Status, Deregister the failed HBA.
Host to Clariion Configurations

Here we are looking at only three possible ways in which a host can be attached to a Clariion. From talking with customers in class, these seem to be the three most common ways in which the hosts are attached.
The key points to the slide are:
1. The LUN, the disk space that is created on the Clariion, that will eventually be assigned to the host, is owned by one of the Storage Processors, not both.
2. The host needs to be physically connected via fibre, either directly attached, or through a switch.
CONFIGURATION ONE
In Configuration One, we see a host that has a single Host Bus Adapter (HBA), attached to a single switch. From the Switch, the cables run once to SP A, and once to SP B. The reason this host is zoned and cabled to both SPs is in the event of a LUN trespass. In Configuration One, if SP A would go down, reboot, etc...the LUN would trespass to SP B. Because the host is cabled and zoned to SP B, the host would still have access to the LUN via SP B. The problem with this configuration is the list of Single Point(s) of Failure. In the event that you would lose the HBA, the Switch, or a connection between the HBA and the Switch (the fibre, GBIC on the switch, etc...), you lose access to the Clariion, thereby losing access to your LUNs.
CONFIGURATION TWO
In Configuration Two, we have a host with two Host Bus Adapters. HBA1 is attached to a switch, and from there, the host is zoned and cabled to SP B. HBA2 is attached to a separate switch, and from there , the host is zoned and cabled to SP A. The path from HBA2 to SP A, is shown as the "Active Path" because that is the path data will leave the host from to get to the LUN, as it is owned by SP A. The path from HBA1 to SP B, is shown as the "Standby Path" because the LUN doesn't belong to SP B. The only time that the host would use the "Standby Path" is in the event of a LUN Trespass. The advantage of using Configuration Two over Configuration One, is that there is no single point of failure.
Now, let's say we install PowerPath on the host. With PowerPath, the host has the potential to do two things. First, it allows the host to initiate the Trespass of the LUN. With PowerPath on the host, if there is a path failure (HBA gone bad, switch down, etc...), the host will issue the trespass command to the SPs, and the SPs will move the LUN, temporarily, from SP A to SP B. The second advantage of PowerPath on a host, is that it allows the host to 'Load Balance' data from the host. Again, this has nothing to do with load balancing the Clariion SPs. We will get there later. However, in Configuration Two, we only have one connection from the host to SP A. This is the only path the host has and will use to move data for this LUN.
CONFIGURATION THREE
In Configuration Three, hardware wise, we have the same as Configuration Two. However, notice that we have a few more cables running from the switches to the Storage Processors. HBA1 is into the switch and zoned and cabled to SP A and SP B. HBA2 is into the switch and zoned and cabled to SP A and SP B. What this does now is to give HBA1 and HBA2 an 'Active Path' to SP A, and HBA1 and HBA2, 'Standby Paths' to SP B. Because of this, the Host now can route data down each active path to the Clariion, allowing the host "Load Balancing" capabilities. Also, the only time a LUN should trespass from one SP to another is if there is a Storage Processor failure. If the host were to lose HBA1, it still has HBA2 with an active path to the Clariion. The same goes for a switch failure and connection failure.
Host Connectivity Limitations

With Configuration One, even though it only has one HBA, that HBA must be connected at least once to SP A and once to SP B. Again, this goes back to the previous blog about access to the Clariion if a LUN were to trespass. Therefore, this host is using two IRRs.
With Configuration Two, this host has one connection from each HBA to one SP Port on each Storage Processor. Even though this host has two HBAs, it is still only using two IRRs. One connection to SPA, one connection to SP B.
With Configuration Three, this host has two connections to the Clariion from each HBA. HBA1 is connected once to SPA and once to SP B. HBA2 is connected once to SP A and once to SP B. This host is using four IRRs because it is connected four times to the Clariion.
In the chart, we are trying to illustrate the maximum number of hosts that can connect to a Clariion based on the host configurations. Again, the more times you connect a host, the more IRRs you use, the less the number of hosts that can be attached to a Clariion. If you are using a CX700, CX3-40 or CX3-80, you have the possibility of hooking up 256 hosts based on each host only having one connection to SP A and one connection to SP B. However, if every host were connected four(4) times, as in Configuration three, that number is cut in half to 128 hosts. If every host were connected to the Clariion eight(8) times, the number is cut again to 64 hosts.
Storage Processor Ports WWNs

Each Storage Processor Port will have a unique World Wide Name associated with it. What we are doing on this page is to “break down” what makes up the SP Port WWN. What I am showing here are the three(3) pieces that make up the WWN. The three(3) pieces are what I am calling the ‘EMC Flag’, the SP Port Identifier, and the Array ID. All SP Port WWNs on Clariions start with the same ‘EMC Flag’ of 50:06:01. When you are looking at the Switch Software that shows the ports on the switch and what is plugged into those ports, anytime you see a World Wide Name that starts with the 50:06:01, you will know that a Clariion SP Port is connected there.
The next “piece” to the World Wide Name, is the SP Port Identifier. On all Clariions, these numbers are the same as well. For instance, if you have 3 Clariions in your environment, every one of those Clariion’s SPA Port 0 World Wide Name would start off 50:06:01:60. And every Clariion’s SP B Port 1 would start off 50:06:01:69. These SP Port Identifiers will not change from Clariion to Clariion.
The last “piece” to the puzzle is the Array ID. This is related to the Unique ID of the Clariion itself. Every Clariion has a unique World Wide Name associated with it. But, that Array ID belongs to every port on that Clariion as it shows above. Now, if you have two(2) Clariions in your environment, you will see two(2) sets of Array IDs. Let’s say you have a Production Clariion and a Development Clariion (I know, no one has that), the Production Clariion could have an Array ID of 10:60:08:74, and the Development Clariion could have an Array ID of 10:60:06:23. So, the Production Clariion’s SP A Port 0 would be 50:06:01:60:10:60:08:74, and the Development Clariion’s SP A Port 0 would be 50:06:01:60:10:60:06:23.
Caching

From the chart above, the amount of Cache that a Clariion contains is based on the model.
Read Caching
First, we will describe the process of when a host issues a request for data from the Clariion.
1.The host issues the request for data to the Storage Processor that owns the LUN. If that data is sitting in Cache on the Storage Processor,
2.The SP sends the data back to the host.
If however, the data is not in Cache, the Storage Processor must go to disk now to retrieve the data. (Step 1 ½ ). It reads the data from the LUN into Read Cache of the owning Storage Processor. (Step 1 ¾ ) before it sends the data to the host.
Write Caching
1.The host writes a block of data to the LUN’s owning Storage Processor.
2.The Storage Processor MIRRORs that data to the other Storage Processor.
3.The owning Storage Processor then sends the Acknowledgement back to the host, that the data is “on disk.”
4.At a later time, the data will be “flushed” from Cache on the SP out to the LUN.
Why does Write Cache MIRROR the data to the other Storage Processor before it sends the acknowledgement back to the host?
This is done to ensure that both Storage Processors have the data in Cache in the event of an SP failure. Let’s say that the owning Storage Processor crashed (again, never happens). If that data was not written to the other Storage Processor’s Cache, that data would be lost. But, because it was written to the other SP Cache, that Storage Processor can now write that data out to the LUN.
This MIRRORing of Write Cache is done through the CMI (Clariion Messaging Interface) Channel which lives on the Clariion.
Cache Allocation

Cache Allocation
In the illustration above, we are seeing again that if data is written to one Storage Processor, it is MIRRORed to the other Storage Processor.
A host that writes data to SP A, will mirror to SP B, and vice versa. So, you will be losing some Cache space to this mirroring. In this example, we are setting SP A’s Write Cache to 1 ½ GB. Which means that over on SP B, 1 ½ GB of Cache space will be taken for the Mirroring of SP A’s Write Cache. The same scenario is set for SP B. The same values are transferred across SPs for Write Cache.
SP Usage
SP Usage is pre-allocated Cache Space that is used by the Clariion for things like pointers/deltas, SnapView, MirrorView. The amount of space that is lost per Storage Processor for SP Usage depends on a couple of things. First, is the type of Clariion you have. Second, what Flare Code you are running on the Clariion. We’ll talk later where to find the Flare Code your Clariion is running.
In this example, we are using 750 MB per Storage Processor as the vaule for SP Usage. To give you some real numbers:
Type of Clariion Flare Code SP Usage:
CX3-80 26 1464 MB
CX3-80 24 1464 MB
CX700 26 884 MB
CX700 24 832 MB
After Write Cache is allocated and SP Usage is taken into account, this leaves us with 250 MB of Cache for Reads.
The nice thing about the Clariion though is that it allows you to change those cache values. Let’s say for instance, that this initial setup above works for you in the mornings when people are writing to a database, but later in the day, the database has more reads. You can take from Write Cache and give the rest to Read Cache. The other nice thing about it is that it can be scripted from the Command Line Interface. Below the chart are the three commands that you can use to change cache.
Command One
Before we can change the values of Cache, we must first disable Cache. This command is the command to disable Write Cache, Read Cache of SP A and SP B. Not only does this disable Cache, it also forces a Flush of Cache to disk. This means that the command prompt will not return immediately. There will be a delay in the command prompt returning until Cache is flushed. As I always say, I cannot give you an amount of time that this will take (two weeks). The answer is going to be….”it depends, you’ll have to test it.”
Command Two
This is the actual setting of Cache command. By default, the setting of Cache is allocated in MegaBytes. By setting Write Cache to 2048 MB (2 GB), we are telling the Clariion to take that number, and divide half of it for SP A Write Cache, and half for SP B Write Cache. We don’t calculate into this the Mirroring of Write Cache, just the actual usable space. Next, we specify the amount for the Read Cache Size of SP A of 1250 MB (1.25 GB) and the Read Cache Size of SP B of 1250 MB (1.25 GB). Read Caching is not Mirrored, so we must specify both SPs Read Cache. Notice how by simply taking ½ GB away from SP A and SP B Write Cache, we can allocate 1 GB more of Cache space to the SPs for Reads.
Command Three
Finally, we have to re-enable Cache. The ones (1) next to –wc, -rca, and –rcb stand for Enabling.
Changing the values of Cache could be done at any time, all day long if you want to, though I wouldn’t recommend it. But, it could prove to be extremely beneficial to performance of the Clariion. Acknowledgements from Writes, and Reading from Cache is going to happen in Nanoseconds as opposed to milliseconds coming from disk.
Another example of why to change Cache could be when Backups are going to occur. Since you will be reading data from Clariion Luns, you could allocate as much Cache to Reads as possible so that the Backup Host could be retrieving data from Cache rather than disk. When the Backups are complete, you could script that the Cache values go back to Production Levels.
Cache Page Size

Here we are discussing the use of the Cache Page Size. We say that it is the same as saying Cache Block Size. Each “Page” or block in Cache is a fixed size. And, in the Clariion, the entire Cache is the same fixed size. Therefore, we feel that this is one of the areas in Cache where knowing your environment (applications, etc) can make a difference. In the diagram above, we are illustrating the use of Cache with three different applications, Oracle, SQL, and Exchange. Next to the applications is a Block Size. We are using these three applications in this diagram because these seem to be the most common applications people come to class with.
Next to the applications is a default Block Size. Again, we are only using these as examples. You want to verify the applications running on the Clariion and their Block Sizes.
There are four different Page Size Settings in Cache for the Clariion, 2 KB, 4 KB, 8 KB, and 16 KB. Let’s start with the default Clariion Page Size of 8 KB. Again, every “Page” in Cache will be 8 KB in size. If we have an application like Oracle running on this Clariion, and Oracle using a default Block Size of 16 KB, that would mean that every Oracle Block of data to the Clariion would be broken into two separate Pages in Cache. With SQL writing to this 8 KB Page Size, it is a one to one ratio, as it is with Exchange, however, with every Exchange Block of data, there is a 4 KB waste of space per block, which could be filling up Cache more rapidly with this “wasted space.”
The next Page Size down shows a 4 KB Page Size for Cache. The nice thing about this size in Cache is that there is no wasted space. Exchange is still in a 1:1 ratio of blocks. However, SQL now has to split into two separate Cache Pages, and Oracle splits into four separate Cache Pages. The good thing about this size is “No Wasted Space.” The down side to this is now we have to listen to the Oracle and SQL admins complain about performance.
So, we set the Page Size to 16 KB to appease the Oracle and SQL admins. Here comes the problem again of wasted space in cache, which, depending on your Clariion, you don’t have a lot of. With the 16 KB Page Size, all of the applications write to one Cache Page. The applications are happy because of this, but we are back to the wasted space. For every Exchange block written to the Clariion, there is a waste of 12 KB Cache space. For every SQL Block, there is a waste of 8 KB Cache Space.
If you are only using one of these applications on the Clariion, great, match the Cache Page Size to that application. If that is not the case, you as the Storage Administrator, will have to decide the Winners and Losers. Next to each of the different page sizes, we have listed the Winners, and the Losers.
In the 8 KB Page Size, SQL and Exchange are winners because from the application point of view, they are a 1:1 ratio. Oracle is a Loser because it is split across two separate blocks in Cache. Another loser in this setting is the Clariion Cache because of the wasted space.
In the 4 KB Page Size, Exchange and Cache are winners because Exchange is again a ratio of 1:1, and no wasted space in Cache. Oracle and SQL are losers because they are written to separate Pages in Cache.
With the 16 KB Page Size, the applications all win. Oracle, SQL and Exchange are all a 1:1 ratio. The big loser in this setting is Cache. Cache is a loser with all of the wasted space.
This, again is one of the places to look at for performance of Cache in a Clariion. Knowing your environment plays a big piece in how things are written to Cache.
Enclosure Types

Enclosure Types
The above page diagrams the back-end structure of a Clariion. How the disks are laid out. Before we discuss the back-end bus structure, we should discuss the different types of enclosures that the Clariion contains.
1.DAE. The Disk Array Enclosure. Disk Array Enclosures exist in all Clariions. DAE’s are the enclosures that house the disks in the Clariion. Each DAE is holds fifteen (15) disks. The disks are in slots that are numbered 0 to 14.
2.DPE. The Disk Processor Enclosure. The Disk Processor Enclosure is in the Clariion Models CX300, CX400, CX500. The DPE is made up of two components. It contains the Storage Processors, and the first fifteen (15) disks of the Clariion.
3.SPE. The Storage Processor Enclosure. The Storage Processor Enclosure is in the Clariion Models CX700 and the CX-3 Series. The SPE is the enclosure that houses the Storage Processors.
The diagrams above lay out the DAE’s back-end bus structure. Data that leaves Cache and is written to disk, or data that is read from disk and placed into Cache travels along these back-end buses or loops. Some Clariions have one back-end bus/loop to get data from enclosure to enclosure. Others have two and four back-end buses/loops to push and pull data from the disks. The more buses/loops, the more expected throughput for data on the back-end of the Clariion.
The Clariion Model on the left is a diagram of a CX300/CX3-10 and CX3-20. These models have a single back-end bus/loop to connect all of the enclosures. The CX300 will have one back-end bus/loop running at a speed of 2 GB/sec, while the CX3-Series Clariions have the ability to run up to 4 GB/sec on the back-end.
The Clariion Model in the middle is a diagram of a CX500. The CX500 has two back-end buses/loops. This gives the CX500, twice the amount of potential throughput for I/Os than the CX300.
The Clariion Model on the right is a diagram of a CX700, CX3-40 and CX3-80. These Clariions contain four back-end buses/loops. The CX3-80 will contain the maximum back-end throughput with all four buses having the ability to run at a 4 GB/sec speed.
Each enclosure has a redundant connection for the bus that it is connected. This is in the event that the Clariion loses a Link Control Card (LCC) that allow the enclosures to move data, or the loss of a Storage Processor. You will see one bus cabled out of SP A and SP B, allowing both SP’s access to each enclosure.
Enclosure Addresses
To determine an address of an enclosure, we need to know two things, what bus it is on, and what number enclosure it is on that bus. On the Clariions in the left diagram, there is only one back-end bus/loop. Every enclosure on these Clariions will be on Bus 0. The enclosure numbers start at zero (0) for the first enclosure and work their way up. On these Clariions, the first enclosure of disks is labeled Bus 0_Enclosure 0 (0_0). The next enclosure of disks is going to be Bus 0_Enclosure 1 (0_1). The next enclosure of disks 0_2, and so on.
The CX500, with two back-end buses will alternate enclosures with the buses. The first enclosure of disks will be the same as the Clariions on the left of Bus 0_Enclosure 0 (0_0). The next enclosure of disks will utilize the other back-end bus/loop, Bus 1. This enclosure is Bus 1_Enclosure 0 (1_0). It is Enclosure 0, because it is the first enclosure of disks on Bus 1. The third enclosure of disks is going to be back on Bus 0, 0_1. The next one up is on Bus 1, 1_1. The enclosures will continue to alternate until the Clariion has all of the supported enclosures. You might ask why it is cabled this way, alternating buses. The reason being is that most companies don’t purchase Clariions fully populated. Most companies buy disks on an as needed basis. By alternating enclosures, you are using all of the back-end resources available for that Clariion.
The Clariions on the right show the four bus structure. The first enclosure of disks is going to be Bus 0_Enclosure 0 (0_0) as all other Clariions. The next enclosure of disks is Bus 1_Enclosure 0 (1_0). Again, using the next available back-end bus, and being the first enclosure of disks on that bus. The third DAE is going to be Bus 2_Enclosure 0 (2_0). The fourth DAE is on the fourth and last back-end bus. It is Bus 3_Enclosure 0 (3_0). From here, we are back to Bus 0 for the next enclosure of disks. Bus 0_Enclosure 1 (0_1). The next DAE is 1_1. The next would be 2_1 if we had one. 3_1, 0_2, and so on until the Clariions were fully populated.
Disk Address
The last topic for this page are the disks themselves. To find a specific disk’s address, we use the Enclosure Address and add the Slot number the disk is in. This gives us the address that is called the B_E_D. Bus_Enclosure_Disk. The Clariion on the left has a disk in slot number 13. The address of that disk would be 0_2_13. The Clariion in the middle has a disk in slot number 10 of Enclosure 1_1. This disk address would be 1_1_10. And the Clariion on the right has a disk in Bus 2_Enclosure 0. It’s address is 2_0_6. And the disk in Bus 1_Enclosure 1 is in slot 9. Address = 1_1_9.
Finally, each Clariion has a limit to the number of disks that it will support. The chart below the diagrams provides the number of how many disks each model can contain. The CX300 can have a maximum of 60 disks, whereas the CX3-80 can have up to 480 disks.
The importance of this page is to know where the disks live in the back of the Clariion in the event of disk failures, and more importantly how you are going to lay out the disks. Meaning, what applications on going to be on certain disks. In order to put that data onto disks, we have to create LUNs (will get to it), which are carved out of RAID Groups (again, getting there shortly). RAID Groups are a grouping of disks. To have a nice balance and to achieve as much performance and throughput on the Clariion, we have to know how the Clariion labels the disks and how the DAE’s are structured.
Cache WaterMarks

WaterMarks :
WaterMarks is what controls writing data out of Cache to disk. It is used to manage how long data stays in Write Cache before it is written to disk.
This diagram is used to describe the types of “Flushing” data to disk, or writing data out of Cache to disk.
The first type of Write Cache Flushing is Idle Flushing.
Idle Flushing is when the Clariion has the ability to take the ‘writes” into cache, send the acknowledgement back to the host that the data is on “disk.” While this is happening, the Clariion can also write data out to disk. The Clariion will try to write to disk in a 64 KB “Chunk.” The cache is absorbing the writes, grouping them together, and writing them to disk. This will come into play later when we discuss how the Clariion formats the disks. This is the perfect case scenario. The Cache takes in the writes, the Clariion has the resources to write the blocks to disk.
The second type of Flushing is WaterMark Flushing.
This is maintained by percentages that you can configure in Cache. The goal with WaterMark Flushing is to keep the Write Cache level between these two percentages. We are using the default Low WaterMark Setting of 60%, and High WaterMark Setting of 80%. These can be changed, and we will discuss that later. With WaterMark Flushing, Cache is going to do it’s best to keep Write Cache between these two levels. As Write Cache hits the High WaterMark, the Clariion tries to flush down to the Low WaterMark. If the amount of Write Cache is constantly between these two levels, the Clariion is doing its job.
The last type of flushing is the “Forced Flush.”
A Forced Flush of Cache results in the Write Cache reaching capacity. The Clariion will no longer accept data into write cache, as there is no more room.
When a Forced Flush occurs, the following take place:
1. The Clariion disables Write Cache.
2. The Clariion begins to destage/flush the write data in Cache out to disk.
3. Now comes the performance issue. With the Clariion disabling Write Cache, any new writes that come in from a host will bypass cache and be written directly to disk. The host/application is now waiting for the acknowledgement to return after the data was written to disk.
4. The Clariion will keep Write Cache disabled until it flushes to the Low WaterMark.
5. Once Write Cache is flushed to the Low WaterMark level, Write Caching is automatically re-enabled.
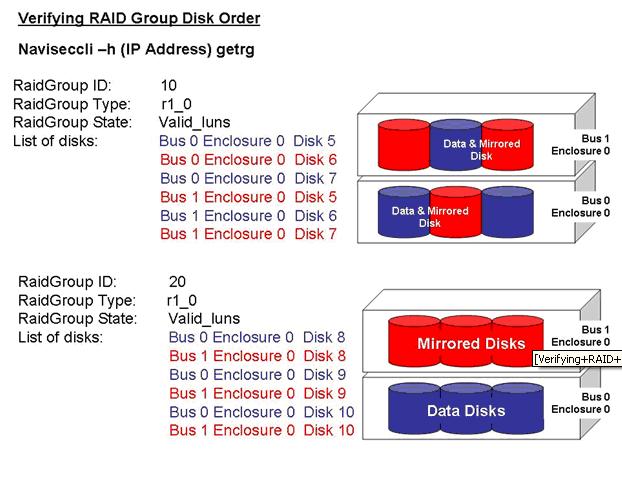
Verifying RAID Group Disk Order
The examples above are from an output of running the get Raid Group command from Navisphere Command Line Interface.
Both RAID Groups are configured as Raid type 1_0.
In an earlier blog we discussed the importance of configuring RAID 1_0 by separating the Data disks and Mirrored Disks across multiple buses and enclosures on the back of the Clariion. This diagram is to show how you could verify if a RAID 1_0 Group is configured correctly or incorrectly.
The reason we are showing the output of the RAID Groups from the command line is this is the only place to truly see if the RAID Groups were configured properly.
The GUI will show the disks as the Clariion sees them in the order of the Bus and Enclosure, not the order you have placed the disks in the RAID Group.

LUN Layout
This diagram shows three different ways in which the same 6 LUNs could be laid out on a RAID Group
In example number 1, the two heavily utilized LUNs have been placed at the beginning and end of the LUNs in the RAID Group, meaning they were the first and last LUNs created on the RAID Group, with lightly utilized LUNs between them. Why this could be a disadvantage to the LUNs, RAID Group, Disks, is that Example 1 would see a much higher rate of Seek Distances at the Disk Level. With a higher Seek Distance rate, comes greater latency, and longer response times for the data. The head has to travel, on average a greater distance between the two busiest LUNs across the disks.
Example 2 has the two heavily utilized LUNs adjacent to each other at the beginning of the RAID Group. While this is the best case scenario for the two busiest LUNs, it could also result in high Seek Distances at the Disk Level because the head would be traveling between the busiest LUNs and then seeking a great distance on the disk when access is needed to the less needed LUNs.
Example 3 shows the heavily utilized LUNs placed in the center of the RAID Group. The advantage to this configuration is the head of the disk would remain between the two busiest LUNs, and then would have a much shorter seek distance to the less utilized LUNs on the outer and inner edge of disks.
The problem with these types of configurations, is that for the most part, it is too late to configure the LUNs in such a way. However, with the use of LUN Migrations in Navisphere, and enough unallocated Disk Space, this could be accomplished while having the LUNs online to the hosts. You will however see an impact on the performance of these LUNs during this Migration process.
But, if performance is an objective, it could be worth it in the long run to make the changes. When LUNs and RAID Groups are initially configured, we usually don’t know what type of Throughput to expect. After monitoring and using Navisphere Analyzer, we could at a later time, begin to move LUNs with heavier needs off of the same Raid Groups, and onto Raid Groups with LUNs not so heavily accessed.

Callculating the Stripe Size of a LUN
To calculate the size of a stripe of data that the Clariion writes to a LUN, we must know how many disks make up the Raid Group, as well as the Raid Type, and how big a chunk of data is written out to a disk. In the illustration above, we have two examples of Stripe Size of a LUN.
The top example shows a Raid 5, five disk Raid Group. We usually hear this referred to as 4 + 1. That means that of the five disks that make up the Raid Group, four of the disks are used to store the data, and the remaining disk is used to store the parity information for the stripe of data in the event of a disk failure and rebuild. Let’s base this on the Clariion settings of a disk format in which it formats the disk into 128 blocks for the Element Size (amount of blocks written to a disk before writing/striping to the next disk in the Raid Group), which is equal to the 64 KB Chunk Size of data that is written to a disk before writing/striping to the next disk in the Raid Group. (see blog titled DISK FORMAT)
To determine the Data Stripe Size, we simply calculate the number of disks in the Raid Group for Data (4) x the amount of data written per disk (64 KB), and get the amount of data written in a Raid 5, Five disk Raid Group (4 + 1) as 256 KB of data. To get the Element Stripe Size, we calculate the number of disks in the Raid Group (4) x the number of blocks written per disk (128 blocks) and get the Element Stripe Size of 512 blocks.
The bottom example illustrates another Raid 5 group, however the number of disks in the Raid Group is nine (9). This is often referred to as 8 + 1. Again, eight (8) disks for data, and the remaining disk is used to store the parity information for the stripe of data.
To determine the Data Stripe Size, we simply calculate the number of disks in the Raid Group for Data (8) x the amount of data written per disk (64 KB), and get the amount of data written in a Raid 5, Five disk Raid Group (8 + 1) as 512 KB of data. To get the Element Stripe Size, we calculate the number of disks in the Raid Group (8) x the number of blocks written per disk (128 blocks) and get the Element Stripe Size of 1024 blocks.
The confusion usually comes across in the terminology. The Stripe Size again is the amount of data written to a stripe of the Raid Group, and the Element Stripe Size is the number of blocks written to a stripe of a Raid Group.

Setting the Alignment Offset on ESX Server and a (Virtual) Windows Server
To add to the layer of confusion, we must discuss what needs to be done when assigning a LUN to an ESX Server, and then creating the (virtual) disk that will be assigned to the (Virtual) Windows Server.
As stated in the previous blog titled Disk Alignment, we must align the data on the disks before any data is written to the LUN itself. We align the LUN on the ESX Server because of the way in which a Clariion Formats the Disks in the 128 blocks per disk (64 KB Chunk) and the metadata written to the LUN from the ESX Server. Although, it is my understanding that ESX Server v.3.5 takes care of the initial offset setting of 128.
The following are the steps to align a LUN for Linux/ESX Server:
Execute the following steps to align VMFS
1. On service console, execute “fdisk /dev/sd”, where sd is the device on which you would like to create the VMFS
2. Type “n” to create a new partition
3. Type “p” to create a primary partition
4. Type “1” to create partition #1
5. Select the defaults to use the complete disk
6. Type “x” to get into expert mode
7. Type “b” to specify the starting block for partitions
8. Type “1” to select partition #1
9. Type “128” to make partition #1 to align on 64KB boundary
10.Type “r” to return to main menu
11.Type “t” to change partition type
12. Type “1” to select partition 1
13. Type “fb” to set type to fb (VMFS volume)
14. Type “w” to write label and the partition information to disk
Now, that the ESX Server has aligned it’s disk, when the cache on the Clariion starts writing data to the disk, it will start writing data to the first block on the second disk, or block number 128. And, because the Clariion formats the disks in 64 KB Chunks, it will write one Chunk of data to a disk.
If we create a (Virtual) Windows Server on the ESX Server, we must take into account that when Windows is assigned a LUN, it will also want to write a signature to the disk. We know that it is a Virtual Machine, but Windows doesn’t know that. It believes it is a real server. So, when Windows grabs the LUN, it will write it’s signature to the disk. See blog titled DISK ALIGNMENT. Again, the problem is that the Windows Signature will take up 63 blocks. Starting at the first block (Block # 128) on the second disk in the RAID Group, the Signature will write halfway across the second disk in the raid group. When Cache begins to write the data out to disk, it will write to the next available block, which is the 64th block on the second disk. In the top illustration, we can see that a 64 KB Data Chunk that is written out to disk as one operation will now span two disks, a Disk Cross. And from here on out for that LUN, we will see a Disk Cross because there was no offset set on the (Virtual) Windows Server.
In the bottom example, we see how the offset was set for the ESX Server, the offset was also set on the (Virtual) Windows Server, and now Cache will write out to a single disk in 64 KB Data Chunks, therefore limiting the number of Disk Crosses.
Again, from the (Virtual) Windows Server we can set the offset for the LUNs using either Diskpart or Diskpar.
To set the alignment using Diskpart, see the earlier Blog titled Setting the Alignment Offset for 2003 Windows Servers(sp1).
To set the alignment using Diskpar:
C:\ diskpar –s 1
Set partition can only be done on a raw drive.
You can use Disk Manager to delete all existing partitions
Are you sure drive 1 is a raw device without any partition? (Y/N) y
----Drive 1 Geometry Information ----
Cylinders = 1174
TracksPerCylinder = 255
SectorsPerTrack = 63
BytesPerSector = 512
DiskSize = 9656478720 (Bytes) = 9209 (MB)
We are going to set the new disk partition.
All data on this drive will be lost. Continue (Y/N) ? Y
Please specify the starting offset (in sectors) : 128
Please specify the partition length (in MB) (Max = 9209) : 5120
Done setting partition
---- New Partition information ----
StatringOffset = 65536
PartitionLength = 5368709120
HiddenSectors = 128
PartitionNumber = 1
PartitionType = 7
As it shows in the bottom illustration from above, the ESX server has set an offset, the (Virtual) Windows Machine has written it’s signature, and has set the offset to start writing data to the first block on the third
disk in the Raid Group.
Setting Raid Group Command Parameters

Setting Cache Command Parameters


Disk Alignment

This is one of the most crucial pieces that we can talk about so far regarding performance. Having the disks that make up the LUN misaligned can be a performance impact of up to 30% on an application. The reason this occurs is because of the “Signature” or MetaData information that a host writes to the beginning of a LUN/Disk. To understand this we must first look at how the Clariion formats the LUNs.
In an earlier blog, we described how the Clariion formats the disks. The Clariion formats the disks in blocks of 128 per disk, which is equivalent to a 64 KB of data that is written to a disk from Cache. Why this is a problem, is that when an Operating System like Windows, grabs the LUN, it wants to initialize the disk, or write a disk signature. The size of this disk signature is 63 blocks, or 31 ½ KB of disk space. Because the Clariion formats the disks in 128 blocks, or 64 KB of disk space, that leaves 65 blocks, or 32 KB of disk space remaining on the first disk for the host to write data. The problem is that the host writes to Cache in whatever block size it does. Cache then holds the data a writes the data out to disk in a 64 KB Data Chunk. Because of the “Signature”, the 64 KB Data Chunk now has to go across two physical disks on the Clariion. Usually, we say that hitting more disks is better for performance. However, with this DISK CROSS, performance will go down on a LUN because Cache is now waiting for an acknowledgement from two disks instead of one disk. If one disk is overloaded with I/O, a disk is failing, etc…this will cause a delay in the acknowledgement back to the Storage Processor. This will be the case from now on when Cache writes every chunk of data out to this LUN. This will impact not only the LUN Cache is writing too, but to every LUN on the Raid Group may be affected.
By using an offset on a LUN from a Host Based Utility, ie Diskpart, or Diskpar for Windows, we are allowing the Clariion to write a 64 KB Data Chunk to one physical disk at a time. Essentially, what we are doing is giving up the remaining disk space on the first physical disk in the Raid Group as the illustration shows above. Window’s still writes it’s “Signature” to the first 63 blocks, but we use Diskpart, or Diskpar to offset the disk space the Clariion Writes to of the remaining space on the first disk. When Cache writes out to disk now, it will begin writing out to the first block on the second disk in the Raid Group, thereby giving the full 128 blocks/64 KB chunk that the Clariion hopes to write out to one physical disk.
The problem with all of this is that this offset or alignment needs to set on a Window’s Disk/LUN before any data is written to the LUN. Once there is data on the LUN, this cannot be done without destroying the existing LUN/data. The only way to now fix this problem is to create a new LUN on the Clariion, assign it to the host, set the offset/alignment, and do a host-based copy/migration. Again, a Clariion LUN Migration is a block for block LUN copy/move. All you are doing with a LUN Migration is moving the problem to a new location on the Clariion.
Windows has two utilities from the Command prompt that can be run to set the offset/alignment, Diskpar and Diskpart.
Diskpar is used for Window’s systems running Windows 2000, or 2003, not using at least Service Pack 1. Diskpar can be downloaded as part of the Resource Kit, and requires through its command line interface that the offset be equal to 128. Diskpar sets the offset in blocks, Since the Clariion formats the disks in 128 blocks, the Clariion will now offset writing to the LUN to block number 128, which is the first block on the second disk.
Diskpart is for Windows Systems running Windows 2003, service pack 1 and up. Diskpart sets the alignment in KiloBytes. Since the Clariion formats the disk in 64 KB, the Clariion will now align the writing to the LUN in 64 KB Chunks, or the first full 64 KB chunk, which is the second physical disk in the Raid Group.
This is also an issue with Linux servers, as an offset will need to set as well. Here again, the number to use is 128, because fdisk uses the number of blocks, not KiloBytes.

The process of a LUN Migration has been available in Navisphere as of Flare Code or Release 16. The LUN Migration is a move of a LUN within a Clariion from one location to another location. It is a two step process. First it is a block by block copy of a “Source LUN” to its new location “Destination LUN”. After the copy is complete, it then moves the “Source” LUNs location to its new place in the Clariion.
The Process of the Migration.
Again, this type of LUN Migration is an internal move of a LUN, not like a SANCopy where a Data Migration occurs between a Clariion and another storage device. In the illustration above, we are showing that we are moving Exchange off of the Vault drives onto Raid Group 10 on another Enclosure in the Clariion. We will first discuss the process of the Migration, and then the Rules of the Migration.
1. Create a Destination LUN. This is going to be the Source LUN’s new location in the Clariion on the disks. The Destination LUN is a LUN which can be on a different Raid Group, on a different BUS, on a different Enclosure. The reason for a LUN Migration might be an instance where we may want to offload a LUN from a busy Raid Group for performance issues. Or, we want to move a LUN from Fibre Drives to ATA Drives. This we will discuss in the RULES portion.
2. Start the Migration from the Source LUN. From the LUN in Navisphere, we simply right-click and select Migrate. Navisphere gives us a window that displays the current information about the Source LUN, and a selection window of the Destination LUN. Once we select the Destination LUN and click Apply, the migration begins. The migration process is actually a two step process. It is a copy first, then a move. Once the migration begins, it is a block for block copy from the Source LUN (Original Location) to the Destination LUN (New Location). This is important to know because the Source LUN does not have to be offline while this process is running. The host will continue to read and write to the Source LUN, which will write to Cache, then Cache writing out to the disk. Because it is a copy, any new write to the source lun will also write to the destination lun. At any time during this process, you may cancel the Migration if the wrong LUN was selected, or to wait until a later time. A priority level is also available to speed up or slow down the process.
3. Migration Completes. When the migration completes, the Source LUN will then MOVE to it’s new location in the Clariion. Again, there is nothing that needs to be done from the host, as it is still the same LUN as it was to begin with, just in a new space on the Clariion. The host doesn’t even know that the LUN is on a Clariion. It thinks the LUN is a local disk. The Destination LUN ID that you give a LUN when creating, will disappear. To the Clariion, that LUN never existed. The Source LUN will occupy the space of the Destination LUN, taking with it the same LUN ID, SP Ownership, and host connectivity. The only things that may or may not change based on your selection of the Destination might be the Raid type, Raid Group, size of the LUN, or Drive Type. The original space that the Source LUN once occupied is going to show as FREE Space in Navisphere on the Clariion. If you were to look at the Raid Group where the Source LUN used to live, under the Partitions tab, you will see the space the original LUN occupied as a Free. The Source LUN is still in the same Storage Group, assigned to the Host as it was before.
Migration Rules
The rules of a Migration as illustrated above are as follows.
The Destination LUN can be:
1. Equal to in size or larger. You can migrate a LUN to a LUN that is the exact same block count size, or to a LUN that is larger in size, so long as the host has the ability to see the additional space once the migration has completed. Windows would need a rescan, reboot of the disks to see the additional space, then using Diskpart, extend the Volume on the host. A host that doesn’t haven’t the ability to extend a volume, would need a Volume Manager software to grow a filesystem, etc.
2. The same or a different drive type. A destination LUN can be on the same type of drives as the source, or a different type of drive. For instance, you can migrate a LUN from Fibre Drives to ATA Drives when the Source LUN no longer needs the faster type drives. This is a LUN to LUN copy/move, so again, disk types will not stop a migration from happening, although it may slow the process from completing.
3. The same or a different raid type. Again, because it is a LUN to LUN copy, raid types don’t matter. You can move a LUN from Raid 1_0 to Raid 5 and reclaim some of the space on the Raid 1_0 disks. Or find that Raid 1_0 better suits your needs for performance and redundancy than Raid 5.
4. A Regular LUN or MetaLUN. The destination LUN only has to be equal in size, so whether it is a regular LUN on a 5 disk Raid 5 group or a Striped MetaLUN spread across multiple enclosures, buses, raid groups for performance is completely up to you.
However, the Destination LUN cannot be:
1. Smaller in size. There is no way on a Clariion to shrink a LUN to allow a user to reclaim space that is not being used.
2. A SnapView, MirrorView, or SanCopy LUN. Because these LUNs are being used by the Clariion to replicate data for local recoveries, replicate data to another Clariion for Disaster Recovery, or to move the data to/from another storage device, they are not available as a Destination LUN.
3. In a Storage Group. If a LUN is in a Storage Group, it is believed to belong to a Host. Therefore, the Clariion will not let you write over a LUN that potentially belongs to another host.

MetaLUNs
The purpose of a MetaLUN is that a Clariion can grow the size of a LUN on the ‘fly’. Let’s say that a host is running out of space on a LUN. From Navisphere, we can “Expand” a LUN by adding more LUNs to the LUN that the host has access to. To the host, we are not adding more LUNs. All the host is going to see is that the LUN has grown in size. We will explain later how to make space available to the host.
There are two types of MetaLUNs, Concatenated and Striped. Each has their advantages and disadvantages, but the end result which ever you use, is that you are growing, “expanding” a LUN.
A Concatenated MetaLUN is advantageous because it allows a LUN to be “grown” quickly and the space made available to the host rather quickly as well. The other advantage is that the Component LUNs that are added to the LUN assigned to the Host can be of a different RAID type and of a different size.
The host writes to Cache on the Storage Processor, the Storage Processor then flushes out to the disk. With a Concatenated MetaLUN, the Clariion only writes to one LUN at a time. The Clariion is going to write to LUN 6 first. Once the Clariion fills LUN 6 with data, it then begins writing to the next LUN in the MetaLUN, which is LUN 23. The Clariion will continue writing to LUN 23 until it is full, then write to LUN 73. Because of this writing process, there is no performance gain. The Clariion is still only writing to one LUN at a time.
A Striped MetaLUN is advantageous because if setup properly could enhance performance as well as protection. Let’s look first at how the MetaLUN is setup and written to, and how performance can be gained. With the Striped MetaLUN, the Clariion writes to all LUNs that make up the MetaLUN, not just one at a time. The advantage of this is more spindles/disks. The Clariion will stripe the data across all of the LUNs in the MetaLUN, and if the LUNs are on different Raid Groups, on different Buses, this will allow the application to be striped across fifteen (15) disks, and in the example above, three back-end buses of the Clariion. The workload of the application is being spread out across the back-end of the Clariion, thereby possibly increasing speed. As illustrated above, the first Data Stripe (Data Stripe 1) that the Clariion writes out to disk will go across the five disks on Raid Group 5 where LUN 6 lives. The next stripe of data (Data Stripe 2), is striped across the five disks that make up RAID Group 10 where LUN23 lives. And finally, the third stripe of data (Data Stripe 3) is striped across the five disks that make up Raid Group 20 where LUN 73 lives. And then the Clariion starts the process all over again with LUN6, then LUN 23, then LUN 73. This gives the application 15 disks to be spread across, and three buses.
As for data protection, this would be similar to building a 15 disk raid group. The problem with a 15 disk raid group is that if one disk where to fail, it would take a considerable amount of time to rebuild the failed disk from the other 14 disks. Also, if there were two disks to fail in this raid group, and it was RAID 5, data would be lost. In the drawing above, each of the LUNs is on a different RAID group. That would mean that we could lose a disk in RAID Group 5, RAID Group 10, and RAID Group 20 at the same time, and still have access to the data. The other advantage of this configuration is that the rebuilds are occurring within each individual RAID Group. Rebuilding from four disks is going to be much faster than the 14 disks in a fifteen disk RAID Group.
The disadvantage of using a Striped MetaLUN is that it takes time to create. When a component LUN is added to the MetaLUN, the Clariion must restripe the data across the existing LUN(s) and the new LUN. This takes time and resources of the Clariion. There may be a performance impact while a Striped MetaLUN is re-striping the data. Also, the space is not available to the host until the MetaLUN has completed re-striping the data.

Access Logix, often referred to as ‘LUN Masking’, is the Clariion term for:
1. Assigning LUNs to a particular Host
2. Making sure that hosts cannot see every LUN in the Clariion
Let’s talk about making sure that every host cannot see every LUN in the Clariion first.
Access Logix is an enabler on the Clariion that allows hosts to connect to the Clariion, but not have the ability to just go out and take ownership of every LUN. Think of this situation. You have ten Window’s Hosts attached to the Clariion, five Solaris Hosts, eight HP Hosts, etc… If all of the hosts were attached to the Clariion (zoning), and there was no such thing as Access Logix, every host could potentially see every LUN after a rescan or 17 reboots by Window’s. Probably not a good thing to have more than one host writing to a LUN at a time, let alone different Operating Systems writing to the same LUNs.
Now, in order for a host to see a LUN, a few things must be done first in Navisphere.
1. For a Host, a Storage Group must be created. In the illustration above, the ‘Storage Group’ is like a bucket.
2. We have to Connect the host to the Storage Group
3. Finally, we have to add the LUNs to the Host’s Storage Group we want the host to see.
From the illustration above, let’s start with the Windows Host on the far left side. We created a Storage Group for the Windows Host. You can name the Storage Group whatever you want in Navisphere. It would make sense to name the Storage Group the same as the Host name. Second, we connected the host to the Storage Group. Finally, we added LUNs to the Storage Group. Now, the host has the ability to see the LUNs, after a rescan, or a reboot.
However, in the Storage Group, when the LUNs are added to the Storage Group, there is a column on the bottom right-side of the Storage Group window that is labeled Host ID. You will notice that as the LUNs are placed into the Storage Group, Navisphere gives each LUN a Host ID number. The host ID number starts at 0, and continues to 255. We can place up to 256 LUNs into a Storage Group. The reason for this, is that the Host has no idea that the LUN is on a Clariion. The host believes that the LUN is a Local Disk. For the host, this is fine. In Windows, the host is going to rescan, and pick up the LUNs as the next available disk. In the example above, the Windows Host picks up LUNs 6 and 23, but to the host, after a rescan/reboot, the host is going to see the LUNs as Disk 4 and Disk 5, which we can now initialize, add a drive letter, format, create the partition, and make the LUN visible through the host.
In the case of the Solaris Host’s Storage Group, when we added the LUNs to the Storage Group, we changed LUN 9s host id to 9, and LUN 15s host id to 15. This allows the Solaris host to see the Clariion LUN 9 as c_t_d 9, and LUN 15 as c_t_d 15. If we hadn’t changed the Host ID number for the LUNs however, Navisphere would have assigned LUN 9 with the Host ID of 0, and LUN 15 with the Host ID of 1. Then the host would see LUN 9 as c_t_d 0 and LUN 15 as c_t_d 15.
The last drawing is an example of a Clustered environment. The blue server is the Active Node of the cluster, and the orange server is the Standby/Passive Node of the cluster. In this example, we created a Storage Group in Navisphere for each host in the Cluster. Into the Active Node Storage Group, we place LUN 8. LUN 8 also went into the Passive Node Storage Group. A LUN can belong to multiple storage groups. The reason for this, is if we only placed LUN 8 in to the Active Node Storage Group, not into the Passive Node Storage Group, and the Cluster failed over to the Passive Node for some reason, there would be no LUN to see. A host can only see what is in it’s storage group. That is why LUN 8 is in both Storage Groups.
Now, if this is not a Clustered Environment, this brings up another problem. The Clariion does not limit who has access, or read/write privileges to a LUN. When a LUN is assigned to a Storage Group, the LUN belongs to the host. If we assign a LUN out to two hosts, with no Cluster setup, we are giving simultaneous access of a LUN to two different servers. This means that each server would assume ownership of the LUN, and constantly be overwriting each other’s data.
We also added LUN 73 to the Active Node Storage Group, and LUN 74 to the Passive Node Storage Group. This allows each server to see LUN 8 for failover purposes, but LUN 73 only belonging to the Active Node Host, and LUN 74 belonging to the Passive Node Host. If the cluster fails over to the Passive Node, the Passive Node will see LUN 8 and LUN 74, not LUN 73 because it is not in the Storage Group.
Notice that LUN 28 is in the Clariion, but not assigned to anyone at the time. No host has the ability to access LUN 28.
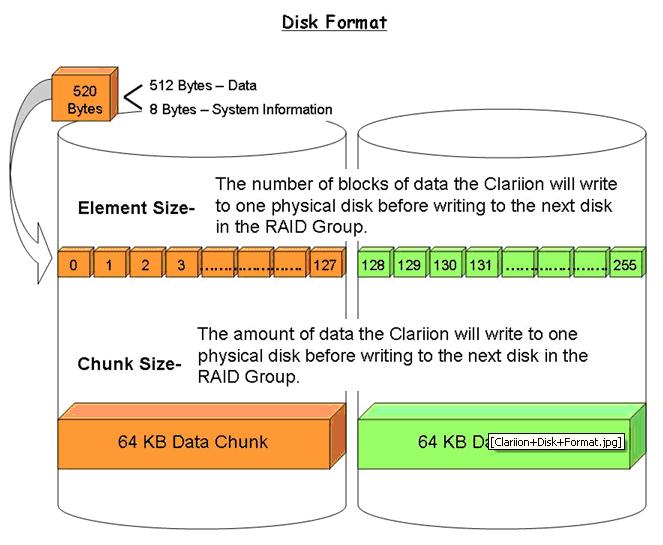
Clariion Disk Format
Disk Format
The Clariion Formats the disks in Blocks. Each Block written out to the disk is 520 bytes in size. Of the 520 bytes, 512 bytes is used to store the actual DATA written to the block. The remaining 8 bytes per block is used by the Clariion to store System Information, such as a Timestamp, Parity Information, Checksum Data.
Element Size – The Element Size of a disk is determined when a LUN is bound to the RAID Group. In previous versions of Navisphere, a user could configure the Element Size from 4 blocks per disk 256 blocks per disk. Now, the default Element Size in Navisphere is 128. This means that the Clariion will write 128 blocks of data to one physical disk in the RAID Group before moving to the next disk in the RAID Group and write another 128 blocks to that disk, so on and so on.
Chunk Size – The Chunk Size is the amount of Data the Clariion writes to a physical disk at a time. The Chunk Size is calculated by multiplying the Element Size by the amount of Data per block written by the Clariion.
128 blocks x 512 bytes of Data per block = 65,536 bytes of Data per Disk. That is equal to 64 KB. So, the Chunk Size, the amount of Data the Clariion writes to a single disk, before writing to the next disk in the RAID Group is 64 KB.

LUNs
As stated in the Host Configuration Slide, a LUN is the disk space that is created on the Clariion. The LUN is the space that is presented to the host. The host will see the LUN as a “Local Disk.”
In Windows, the Clariion LUN will show up in Disk Manager is Drive #, which the Windows Administrator can now format, partition, assign a Drive Letter, etc…
In UNIX, the Clariion LUN will show up as a c_t_d_ address, which the UNIX Administrator can now mount.
A LUN is owned by a single Storage Processor at a time. When creating a LUN, you assign the LUN to a Storage Processor, SPA, SPB or let the Clariion choose by selecting AUTO. The Auto option lets the Clariion assign the next LUN to the Storage Processor with the fewest number of LUNs.
The Properties/Settings of LUN during creation/binding are:
1. Selecting which RAID Group the LUN will be bound to.
2. If it is the first LUN created on a RAID Group, the first LUN will set the RAID Type for the entire RAID Group. Therefore, when creating/binding the first LUN on a RAID Group, you can select the RAID Type.
3. Select a LUN Id or number for the LUN.
4. Specify a REBUILD PRIORITY for the LUN in the event of a Hot Spare replacing a failed disk.
5. Specify a VERIFY PRIORITY for the LUN to determine the speed in which the Clariion runs a “SNIFFER” in the background to scrub the disks.
6. Enable or Disable Read and Write Cache at the LUN level. An example might be to disable Read/Write Cache for a LUN that is given to a Development Server. This ensures that the Development LUNs will not use the Cache that is needed for Production Data.
7. Enable Auto Assign. By default this box is unchecked in Navisphere. That is because you will have some sort of Host Based Software that will manage the trespassing and failing back of a LUN.
8. Number of LUNs to Bind. You can bind up to 128 LUNs on a single RAID Group.
9. SP Ownership. You can select if you want your LUN(s) to belong to SP A, SP B, or the AUTO option in which the Clariion decides LUN ownership based on the Storage Processor with the fewest number of LUNs.
10. LUN Size. You specify the size of a LUN by entering the numbers, and selecting MB (MegaBytes), GB (GigaBytes), TB (TeraBytes), or Block Count to specify the number of blocks a LUN will be. This is critical for SnapView Clones, and MirrorView Secondary LUNs.
The amount of LUNs a Clariion can support is going to be Clariion specific.
CX 300 – 512 LUNs
CX3-20 – 1024 LUNs
CX3-80 – 2048 LUNs

Order of Disks in RAID Group for RAID 1_0.
When creating a RAID 1_0 Raid Group, it is important to know and understand the order of the drives as they are put into the RAID Group will absolutely make a difference in the Performance and Protection of that RAID Group. If left to the Clariion, it will simply choose the next disks in the order in which is sees the disks to create the RAID Group. However, this may not be the best way to configure a RAID 1_0 RAID Group. Navisphere will take the next disks available, which are usually right next to one another in the same enclosure.
In a RAID 1_0 Group, we want the RAID Group to span multiple enclosures as illustrated above. The reason for this is as we can see, the Data Disks will be on Bus 1_Enclosure 0, and the Mirrored Data Disks will be on Bus 2_Enclosure 0. The advantage of creating the RAID Group this way is that we place the Data and Mirrors on two separate enclosures. In the event of an enclosure failure, the other enclosure could still be alive and maintaining access to the data or the mirrored data. The second advantage is Performance. Performance could be gained through this configuration because you are spreading the workload of the application across two different buses on the back of the Clariion.
Notice the order in which the disks were placed into the RAID 1_0 Group. In order to for the disks to be entered into the RAID Group in this order, they must be manually entered into the RAID Group this way via Navisphere or the Command Line.
The first disk into the RAID Group receives Data Block 1.
The second disk into the RAID Group receives the Mirror of Data Block 1.
The third disk into the RAID Group receives Data Block 2.
The fourth disk into the RAID Group receives the Mirror of Data Block 2.
The fifth disk into the RAID Group received Data Block 3.
The sixth disk into the RAID Group receives the Mirror of Data Block 3.
If we let the Clariion choose these disks in its particular order, it would select them:
First disk – 1_0_0 (Data Block 1)
Second disk – 1_0_1 (Mirror of Data Block 1)
Third disk – 1_0_2 (Data Block 2)
Fourth disk – 2_0_0 (Mirror of Data Block 2)
Fifth disk – 2_0_1 (Data Block 3)
Sixth disk – 2_0_2 (Mirror of Data Block 3)
This defeats the purpose of having the Mirrored Data on a different enclosure than the Data Disks.

RAID GROUPS and RAID Types
The above slide illustrates the concept of creating a RAID Group and the supported RAID types of the Clariions.
RAID Groups
The concept of a RAID Group on a Clariion is to group together a number of disks on the Clariion into one big group. Let’s say that we need a 1 TB LUN. The disks we have a 200 GB in size. We would have to group together five (5) disks to get to the 1 TB size needed for the LUN. I know we haven’t taken into account for parity and what the RAW capacity of a drive is, but that is just a very basic idea of what we mean by a RAID Group. RAID Groups also allow you to configure the Clariion in a way so that you will know what LUNs, Applications, etc…live on what set of disks in the back of the Clariion. For instance, you wouldn’t want an Oracle Database LUN on the same RAID Group (Disks) as a SQL Database running on the same Clariion. This allows you to create a RAID Group of a # of disks for the Oracle Database, and another RAID Group of a different set of disks for the SQL Database.
RAID Types
Above are the supported RAID types of the Clariion.
RAID 0 – Striping Data with NO Data Protection. The Clariions Cache will write the data out to disk in blocks (chunks) that we will discuss later. For RAID 0, the Clariion writes/stripes the data across all of the disks in the RAID Group. This is fantastic for performance, but if one of the disks fail in the RAID 0 Group, then the data will be lost because there is no protection of that data (i.e. mirroring, parity).
RAID 1 – Mirroring. The Clariion will write the Data out to the first disk in the RAID Group, and write the exact data to another disk in that RAID 1 Group. This is great in terms of data protection because if you were to lose the data disk, the mirror would have the exact copy of the data disk, allowing the user to access the disk.
RAID 1_0 – Mirroring and Striping Data. This is the best of both worlds if set up properly. This type of RAID Group will allow the Clariion to stripe data and mirror the data onto other disks. However, the illustration above of RAID 1_0, is not the best way of configuring that type of RAID Group. The next slide will go into detail as to why this isn’t the best method of configuring RAID 1_0.
RAID 3 – Striping Data with a Dedicated Parity Drive. This type of RAID Group allows the Clariion to stripe data the first X number of disks in the RAID Group, and dedicate the last disk in the RAID Group for Parity of the data stripe. In the event of a single drive failure in this RAID Group, the failed disk can be rebuilt from the remaining disks in the RAID Group.
RAID 5 – Striping Data with Distributed Parity. RAID type 5 allows the Clariion to distribute the Parity information to rebuild a failed disk across the disks that make up the RAID Group. As in RAID 3, in the event of a single drive failure in this RAID Group, the failed disk can be rebuilt from the remaining disks in the RAID Group.
RAID 6 – Striping Data with Double Parity. This is new to Clariion world starting in Flare Code 26 of Navisphere. The simplest explanation of RAID 6 we can use for RAID 6 is the RAID Group uses striping, such as RAID 5, with double the parity. This allows a RAID 6 RAID Group to be able to have two drive failures in the RAID Group, while maintaining access to the LUNs.
HOT SPARE – A Dedicated Single Disk that Acts as a Failed Disk. A Hot Spare is created as a single disk RAID Group, and is bound/created as a HOT SPARE in Navisphere. The purpose of this disk is to act as the failed disk in the event of a drive failure. Once a disk is set as a HOT SPARE, it is always a HOT SPARE, even after the failed disk is replaced. In the slide above, we list the steps of a HOT SPARE taking over in the event of a disk failure in the Clariion.
1. A disk fails – a disk fails in a RAID Group somewhere in the back of the Clariion.
2. Hot Spare is Invoked – a Clariion dedicated HOT SPARE acts as the failed disk in Navisphere. It will assume the identity of the failed disk’s Bus_Enclosure_Disk Address.
3. Data is REBUILT Completely onto the Hot Spare from the other disks in the RAID Group – The Clariion begins to recalculate and rebuild the failed disk onto the Hot Spare from the other disks in the RAID Group, whether it be copying from the MIRRORed copy of the disk, or through parity and data calculations of a RAID 3 or RAID 5 Group.
4. Disk is replaced – Somewhere throughout the process, the failed drive is replaced.
5. Data is Copied back to new disk – The data is then copied back to the new disk that was replaced. This will take place automatically, and will not begin until the failed disk is completely rebuilt onto the Hot Spare.
6. Hot Spare is back to a Hot Spare – Once the data is written from the Hot Spare back to the failed disk, the Hot Spare goes back to being a Hot Spare waiting for another disk failure.
Hot Spares are going to be size and drive type specific.
Size. The Hot Spare must be at least the same size as the largest size disk in the Clariion. A Hot Spare will replace a drive that is the same size or a smaller size drive. The Clariion does not allow multiple smaller Hot Spares replace a failed disk.
Drive Type Specific. If your Clariion has a mixture of Drive Types, such as Fibre and S.ATA disks, you will need Hot Spares of those particular Drive Types. A Fibre Hot Spare will not replace a failed S.ATA disk and vice versa.
Hot Spares are not assigned to any particular RAID Group. They are used by the Clariion in the event of any failure of that Drive Type. The recommendation for Hot Spares is one (1) Hot Spare for every thirty (30) disks.
There are multiple ways to create a RAID Group. One is via the Navisphere GUI, and the other is through the Command Line Interface. In later slides we will list the commands to create a RAID Group.